6 SQL Data Warehouse Solutions For Big Data Analysts (With Their Pros And Cons)

Are you confused about which SQL Query tool is best for your organization?
In this technically dynamic world where data is king, many data analysts are faced with making the difficult choice of what querying engines to employ.
Beyond that, they are tasked with sifting through the data storage systems these engines support, and weighing what they stand to gain (or lose as the case may be). How do data analysts cope?
Enter, stage left: Andrew is a big data engineer at CDS Solutions. He needs to employ an optimized system to manage the increased data demands his company is experiencing. And he has to come up with a near perfect proposition in his next meeting with his superior.
What can he do to make himself look good in front of his employer at this point? Nothing would solve Andrew’s dilemma more quickly than a detailed comparison of the data querying tools currently popular in the big data analytics sphere.
Without further ado, let’s make it easier for you to decide what’s right for your company.
First on our list of big data tools is Cloudera Impala.

1. Cloudera Impala
Impala is a real time, Apache licensed, open source, massively parallel processing (MPP) SQL on Hadoop querying engine written in C++ programming language and currently shipped by Cloudera, MapR, Amazon and Oracle.
Pros
- Impala provides real time querying on data stored on Hadoop clusters.
- It’s fast. The fact that it doesn’t use MapReduce to execute its queries makes it faster than Hive.
- It uses HiveQL and SQL-92, making it easy for data analysts coming from a RDBMS (Relational DataBase Management Systems) background to understand and use.
- Enterprise installation is supported because it is backed by Cloudera — an enterprise big data vendor.
Cons
- Impala only has support for Parquet, RCFile, SequenceFIle, and Avro file formats. So if your data is in ORC format, you will be faced with a tough job transitioning your data.
- Supports only Cloudera’s CDH, MapR, and AWS platforms.

2. Apache Hive
Hive is an Apache licensed, open-source query engine written in Java programming language used for summarizing, analyzing and querying data stored on Hadoop. Though it was initially introduced by Facebook, it was later open-sourced.
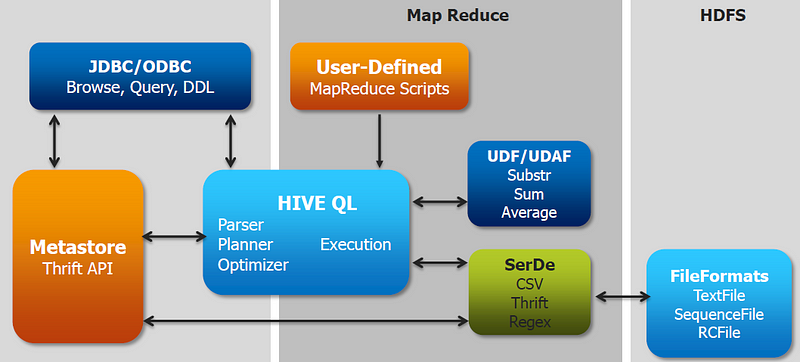
Image Source — Apache Hive Architecture
Pros
- It is stable as it has been around for over five years.
- Hive is also open-source with a great community should you need help using it.
- It uses HiveQL, a SQL-like querying language which can be easily understood by RDBMS experts.
- Supports Text File, RCFile, SequenceFile, ORC, Parquet, and Avro file formats.
Cons
- Hive relies on MapReduce to execute queries which makes it relatively slow compared to querying engines like Cloudera Impala, Spark or Presto.
- Hive only supports structured data. So if your data is largely unstructured, Hive isn’t an option.
Another relevant SQL querying tool to consider is Apache Spark.

3. Apache Spark
Apache Spark is a cluster computing framework that runs on Hadoop. It was introduced by UC Berkeley and written in Scala programming language. Apache Spark comes bundled with Spark SQL, MLlib, GraphX and Spark Streaming which makes it a complete framework on Hadoop.
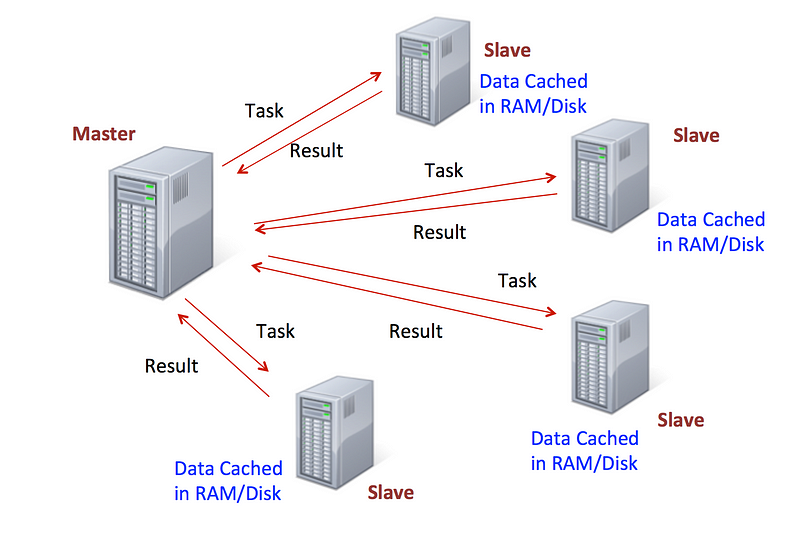
Image Source — How Spark executes a job
Pros
- It is very fast. Spark SQL executes batch queries in the Spark framework 10–100 times faster than Hive with MapReduce.
- Spark provides full compatibility with Hive data, queries, and user defined functions (UDF).
- Spark provides APIs (Application Programming Interfaces) in various languages (Java, Scala, Python) which makes it possible for developers to write applications in those languages.
- Apache Spark and Spark SQL boasts a larger open-source community support than Presto.
Cons
- Apache Spark consumes lots of RAM which makes it expensive in terms of cost.
- It is still maturing, and as such, it is not considered to be stable yet.
Next on the list is Presto. (And we’ve written quite extensively about this engine here and here).

4. Presto
Presto is another massively parallel processing (MPP), open source, SQL on Hadoop querying engine developed by Facebook to query databases on different sources with high speed irrespective of the volume, velocity, and variety of data they contain. It is currently being backed by Teradata and has been employed for use by AirBnB, Dropbox, Netflix, and Uber.
Pros
- Presto supports Text, ORC, Parquet and RCFile file formats. This makes it a great query engine of choice without worrying about transforming your existing data into a new format.
- It works well with Amazon S3 storage and queries data from any source at the scale of petabytes simultaneously and in seconds.
- Great support from the open-source community will ensure Presto is around for much longer.
- Enterprise support is provided by Teradata — a big data analytics and marketing applications company.
Cons
- Being largely open source, it is not advisable to deploy Presto if you think you aren’t capable of supporting and debugging issues with Presto yourself except you decide to work with a vendor like Teradata.
- It doesn’t have its own storage layer, so queries involving inserts or writing to the HDFS are not supported.

BigQuery is a cloud database solution provided by Google which executes queries on large amounts of data in seconds. Being a full database solution and not just another query engine means that it provides its own storage, a query engine, and also uses SQL-like commands to run queries against data stored in it.
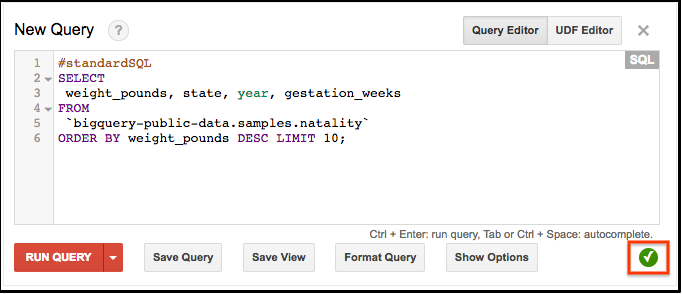
Image Source — BigQuery web UI
Pros
- I would refer to Google BigQuery as a plug and play solution for big data in that you don’t worry about server management here. You only import your data in its own storage and begin querying your data while it handles performance, memory allocation, and CPU optimization implicitly.
- It has a strong backing from Google making it a very stable product.
- BigQuery supports standard SQL syntax.
- Moving data from other cloud storage solutions like Amazon S3 into GCS (Google Cloud Storage) is easy and hassle-free using the transfer manager.
- Great support for enterprise users.
Cons
- It could become very expensive if you query your data a lot — because Google also charges per data processed on a query.
- Queries with lots of joins are not that fast.
- You have to move your data into BigQuery’s storage system before you can query your data with it.
Last but not least, Amazon Redshift.

6. Amazon Redshift
Amazon Redshift is a fast and powerful, petabyte-scale, cloud-based data warehousing solution which forms part of the Amazon Web Services (AWS) cloud-computing platform. It was introduced by Amazon and is currently being managed by them as well.
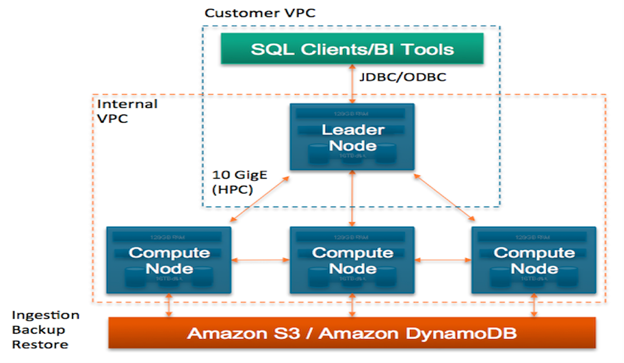
Image Source — Amazon Redshift architecture
Pros
- Redshift has great support for enterprise users. Like Google BigQuery, it is a cloud-based complete data warehousing solution.
- It works well with Amazon S3 being a part of the Amazon cloud computing platform.
- It is easily scalable.
- It supports almost all standard SQL features.
Cons
- It could also get very expensive considering the fact that Amazon bills you for storage space as well as server requirements (CPU, RAM etc.).
- Redshift isn’t serverless like BigQuery, so you have to account for the amount of resources as well as the allocation of said resources that your data cluster would require.
In Summary
Various use cases will demand different solutions for analysing, storing and querying your organization’s data, so it will be difficult for me to proffer a solution for your personal needs.
If you decide to go the open source SQL-on Hadoop route, be prepared to have a team of competent data engineers that can manage and debug in-house. If you prefer the enterprise cloud-based solutions, be prepared to understand the cost implications as the bills tend to rise as your data increases in size.
Whichever route you choose, make sure you understand fully well what you are getting into and plan your tradeoffs with respect to the benefits each route provides.
With these comparisons under your belt, you (and Andrew) can prepare an incredibly detailed presentation for your boss. The higher-ups will be impressed with your expertise, and your colleagues will feel secure knowing you took the time to find them the best solution possible. When you make an informed choice, you enable your unique team to look their best on the job.
Shameless plug
Our product, Rakam, is a solution that allows you to build your own analytics service using Presto. It provides an analytics infrastructure on top of your AWS account. You install Rakam on your cloud provider (AWS, Google Cloud, Azure etc.) and use our API (api link) and SDKs (SDKs link), and we store your data in ORC format in your cloud provider and use Presto to run SQL queries on top of your data. We have custom modules that take care of schema evolution, high availability and automation tools for scaling your Presto cluster. Our system is near real-time; you will be able to query your data in a minute, design your workflow, and create reports and dashboard with Rakam within minutes.


Comments
Post a Comment